
Gamalon lanza una técnica que reconoce conceptos claves de forma mucho más eficiente, y ya tiene dos productos en el mercado. Si consigue ampliar sus aplicaciones, el impacto podría ser enorme
Will Knight
Mariátegui
25/05/17
El aprendizaje automático se está volviendo extremadamente potente, pero para resultar útil todavía depende de enormes cantidades de datos.
Ya es posible entrenar un algoritmo de aprendizaje profundo para que reconozca un gato con el mismo nivel de precisión que un amante de la especie. Pero para ello debe ser alimentado con decenas o incluso cientos de miles de imágenes de felinos para entender su gran variación de tamaños, formas, texturas, iluminaciones y orientaciones. Una estrategia más eficiente consistiría en que, igual que hacen las personas, los algoritmos se hicieran su propia idea de los elementos que hacen que un gato sea un gato, lo cual necesitaría muchos menos ejemplos.
Una start-up de Boston (EEUU) llamada Gamalon ha desarrollado una tecnología capaz de hacer justo esto en algunas situaciones, y ha lanzando dos productos basados en este enfoque.
Si la técnica consigue ser aplicada a más escenarios, su impacto podría ser enorme. La capacidad de aprender a partir de menos datos podría permitir que los robots exploren y comprendan nuevos entornos muy rápidamente, y que los ordenadores aprendan nuestras preferencias sin necesidad de compartir nuestros datos.
Gamalon emplea una técnica que denomina "síntesis de métodos Bayesianos" para desarrollar algoritmos capaces de aprender a partir de menos ejemplos. La probabilidad Bayesiana, nombrada por el matemático Thomas Bayes del siglo XVIII, proporciona un marco matemático para refinar predicciones sobre el mundo basadas en la experiencia. El sistema de Gamalon utiliza la programación probabilística (o código que considera probabilidades en lugar de variables específicas) para desarrollar un modelo predictivo que explique un conjunto de datos específico. Con sólo un par de ejemplos, el programa probabilístico es capaz de determinar que es muy probable que los gatos tengan orejas, bigotes y cola. A medida que recibe más ejemplos, el código se reescribe de acuerdo a las nuevas probabilidades. Esto proporciona una excelente manera de aprender la información principal de los datos.
Las técnicas de programación probabilística existen desde hace tiempo. En 2015, por ejemplo, un equipo del Instituto Tecnológico de Massachusetts (MIT, EEUU) y la Universidad de Nueva York (EEUU) utilizó métodos probabilísticos para que los ordenadores aprendiesen a reconocer caracteres escritos y objetos tras observar un único ejemplo (ver Nace el ordenador capaz de leer un texto escrito a mano). Pero el enfoque no ha pasado de mera curiosidad académica.
Este enfoque se enfrenta a algunos retos computacionales, ya que el programa debe considerar muchas explicaciones posibles distintas, señala el investigador de la Universidad de Nueva York Brenden Lake, quien lideró el trabajo de 2015.
Aun así, según Lake, en teoría el enfoque tiene mucho potencial porque puede automatizar aspectos del desarrollo de un modelo de aprendizaje automático. "La programación probabilística hará que el aprendizaje de máquinas resulte mucho más fácil para investigadores y desarrolladores", afirma Lake. "Tiene el potencial de encargarse de las partes difíciles [de la programación] de forma automática", añade.
Desde luego existen importantes incentivos para desarrollar enfoques de aprendizaje automático más fáciles de utilizar y que requieran menos datos. El aprendizaje automático actual incluye adquirir un gran conjunto de datos brutos que a menudo deben ser etiquetados a mano. Y para ejecutarlo, son necesarios grandes centros de datos con procesadores informáticos que trabajan en paralelo durante horas o días. "Sólo hay un puñado de empresas lo suficientemente grandes como para permitirse hacerlo en serio", señala el cofundador y CEO de Gamalon, Ben Vigoda.
En teoría, el enfoque de Gamalon también podría facilitar la creación de un modelo de aprendizaje automático. Perfeccionar un algoritmo de aprendizaje profundo requiere una gran cantidad de experiencia matemática y de aprendizaje automático. "Hay algo de magia negra en las labores para configurar estos sistemas", dice Vigoda. Con el enfoque de Gamalon, un programador podría entrenar un modelo mediante ejemplos significativos.
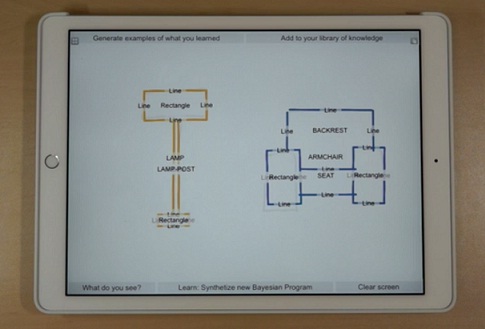
Vigoda hizo una demostración de una app de dibujo que emplea la técnica a MIT Technology Review. El enfoque es similar al que lanzó Google el año pasado, que utiliza el aprendizaje profundo para reconocer el objeto que intenta dibujar una persona (ver Si quiere saber cómo funciona la IA, dibuje un pato para una red neuronal). Pero mientras que la app de Google necesita ver un dibujo que concuerde con los que ha visto antes, la versión de Gamalon utiliza un programa probabilístico para reconocer las características claves de un objeto. Por ejemplo, un programa entiende que un triángulo colocado encima de un cuadrado probablemente será una casa. Esto significa que incluso si el dibujo varía mucho de los que haya visto antes, siempre que incluya esas características, la app adivinará la respuesta correcta.
La técnica podría tener importantes aplicaciones comerciales a corto plazo. Los primeros productos de la empresa utilizan la síntesis de métodos Bayesianos para reconocer conceptos dentro del arte.
Uno de los nuevos servicios de la compañía, llamado Gamalon Structure, puede extraer conceptos de textos en bruto de manera más eficaz de lo que normalmente es posible. Por ejemplo, puede examinar la descripción del fabricante de un televisor y determinar qué producto describe, la marca, el nombre, la resolución, el tamaño y otras características. El otro servicio, Gamalon Match, categoriza los productos y precios del inventario de una tienda. En ambos casos, incluso cuando se utilizan acrónimos o abreviaciones distintas para un producto o prestación, el sistema aprende a reconocerlos rápidamente.
Vigoda cree que esta capacidad de aprender tendrá otros beneficios prácticos. Un ordenador podría aprender sobre los intereses de un usuario sin requerir una cantidad poco práctica de datos ni horas de entrenamiento. Y si el aprendizaje automático pudiera ejecutarse de manera eficiente desde el smartphone o portátil del usuario ya no sería necesario facilitar datos personales a las grandes empresas. Y un robot o coche autónomo podría aprender sobre un nuevo obstáculo sin necesitar ver cientos de miles de ejemplos.
Foto: Una 'app' desarrollada por Gamalon reconoce objetos tras ver tan sólo un par de ejemplos. Un programa de aprendizaje reconoce conceptos más sencillos como líneas y rectángulos.
technologyreview.es| Traducido por Teresa Woods
Comentarios